Daten sind Produktionsfaktor und spielen in allen heutigen Unternehmen eine wichtige Rolle bei der Erstellung von Produkten und Dienstleistungen. Daten können in der Produktion auf verschiedene Arten genutzt werden, wie beispielsweise bei der Verbesserung von Produktionsprozessen, der Optimierung von Lieferketten oder der Personalisierung von Produkten und Dienstleistungen. Insbesondere in der Industrie 4.0 werden Daten zunehmend als wichtiger Produktionsfaktor betrachtet, da sie die Grundlage für viele innovative Technologien wie das Internet der Dinge, künstliche Intelligenz und automatisierte Systeme bilden. Diese Technologien können dazu beitragen, die Effizienz, Qualität und Flexibilität von Produktionsprozessen zu verbessern und so die Wettbewerbsfähigkeit von Unternehmen zu steigern.
Es ist jedoch wichtig zu beachten, dass Daten allein nicht ausreichen, um einen Mehrwert für Unternehmen zu schaffen. Um Daten als Produktionsfaktor effektiv zu nutzen, müssen Unternehmen in der Lage sein, sie zu sammeln, zu speichern, zu verarbeiten und zu analysieren, um Erkenntnisse und Einsichten zu gewinnen, die zur Verbesserung von Geschäftsprozessen beitragen. Daher ist es für Unternehmen von großer Bedeutung, ihre Datenstrategie betreffend der richtigen Datenarchitektur und ihre technologischen Fähigkeiten zu verbessern, um den vollen Nutzen aus dem Einsatz von Daten als Produktionsfaktor zu ziehen.
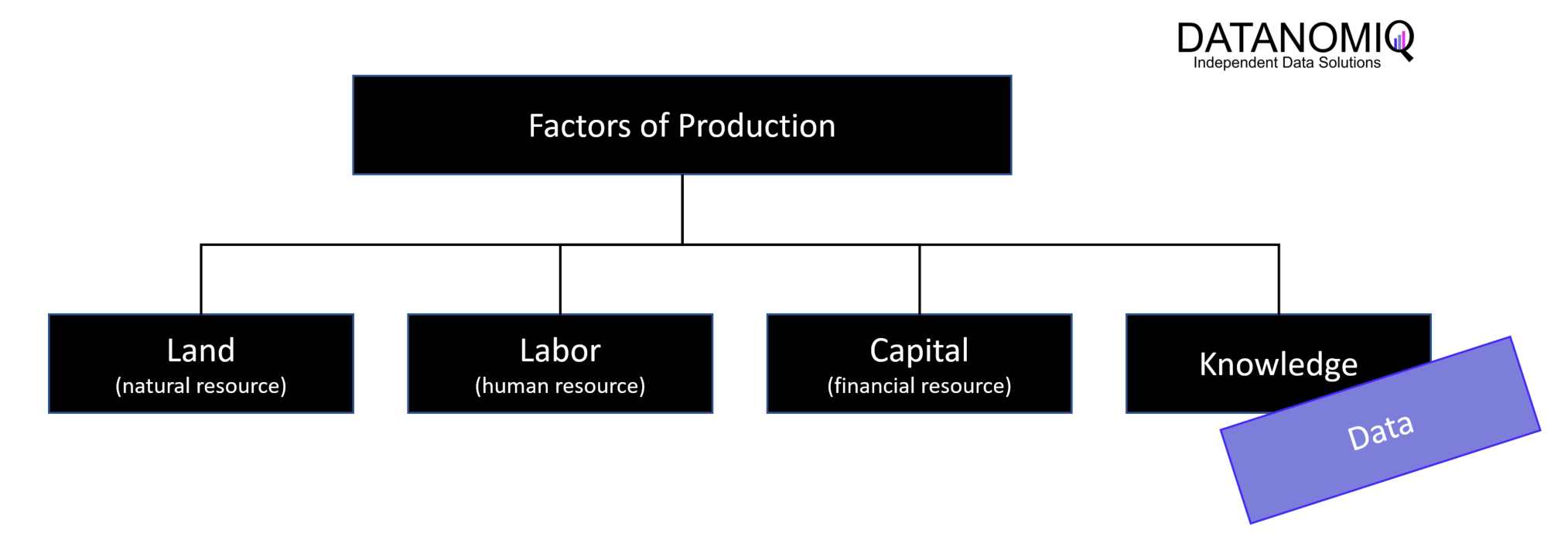
Um Daten als Produktionsfaktor richtig nutzen zu können, müssen diese allen Stakeholdern effektiv und effizient verfügbar gemacht werden.
Datenverfügbarkeit, -Qualität und -Transparenz steigert die Unternehmensbewertung
Transparente Prozesse verbessern die Zusammenarbeit zwischen Abteilungen, qualitative Daten steigern die Effizienz von Geschäftsprozessen und verringern das Risiko von Fehlern. Eine hohe Datenqualität ist zudem wichtig, um fundierte Entscheidungen treffen zu können und mögliche rechtliche Probleme zu vermeiden. Die Verfügbarkeit von Daten in hoher Qualität und die Transparenz über Prozesse – auch über jene für die Datenaufbereitung selbst – steigern in jedem Fall die Unternehmensbewertung, da Investoren und Interessengruppen die Leistung des Unternehmens genauer, sicherer und vor allem schneller beurteilen können und effektive Prozesse zur Rentabilitätssteigerung und Zukunftsbewältigung beitragen können.
Datenverfügbarkeit für Business Intelligence
Transparenz über Prozesse und die Qualität von Daten spielt eine zentrale Rolle für Unternehmen, weil sie direkte Auswirkungen auf die Entscheidungsfindung, die Effizienz und die Zuverlässigkeit von Geschäftsprozessen haben. Business Intelligence (BI) unterstützt die Entscheidungsfindung auf verschiedene Arten, indem es den Zugriff auf relevante Daten und Informationen erleichtert. Eine hohe Datenqualität ist dabei von entscheidender Bedeutung, da Unternehmen heute mehr Daten denn je sammeln, um fundierte Entscheidungen treffen zu können. Wenn Daten unvollständig, ungenau oder veraltet sind, können sie zu falschen Entscheidungen führen, die sich negativ auf das Unternehmen auswirken können. Darüber hinaus kann eine schlechte Datenqualität auch rechtliche Probleme verursachen, wenn Unternehmen beispielsweise gegen Datenschutzgesetze verstoßen.
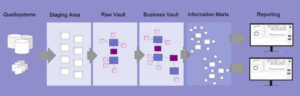
Für Analysen und Reports der Business Intelligence müssen Daten aus verschiedenen Quellen zusammengeführt, bereinigt, konsolidiert und in zielführende Datenmodelle aufbereitet werden. Hier herrscht das Prinzip Schema on Write vor, welches bedeutet, dass bevor Daten in jene Datenmodelle integriert werden können, die dafür notwendigen Datenbank-Tabellen erst angelegt werden müssen, mit den richtigen Meta-Beschreibungen über Datentypen, Speichergrößen und vorgeschriebenen Verknüpfungen (Relationen). Die Aufwände, Daten für BI vorzubereiten, sind folglich bereits vor der eigentlichen Nutzung recht hoch.
Datenverfügbarkeit für Process Mining
Process Mining, oder auch Process Intelligence, ist eine Unterform der Business Intelligence und ermöglicht es Organisationen, Prozesse genauer zu überwachen und zu messen, was zu einer Verbesserung der Prozessqualität und Einhaltung von Standards führen kann. Unternehmen können damit sicherstellen, dass ihre Prozesse effektiv und effizient sind und dass sie die erforderlichen Qualitätsstandards erfüllen. Durch die Analyse von Prozessdaten können Unternehmen Engpässe, Bottlenecks und ineffiziente Arbeitsabläufe identifizieren. Diese Erkenntnisse können verwendet werden, um Prozesse zu optimieren und zu verbessern, was zu einer höheren Effizienz und Produktivität führen kann. Auch die Überwachung und Fehleranalyse für Audit / Compliance sind Anwendungszwecke.
Ähnliche wie für die klassische Business Intelligence müssen auch für Process Mining Daten verfügbar sein, qualitativ aufbereitet und in Datenmodelle (Event Logs) gefasst werden.
Datenverfügbarkeit für Data Science und Artificial Intelligence
Unternehmen können nur dann von Data Science und Artificial Intelligence (AI) profitieren, wenn die dafür benötigten Daten verfügbar und für die Data Science Teams und Machine Learning Engineers überhaupt leicht zugänglich sind. Data Science arbeiten auch mit Daten nach dem Konzept Schema on Read (deutsch: Schema bei Lesezugriff) ist ein Ansatz für die Verarbeitung von Daten in Big-Data-Umgebungen. Es bezieht sich darauf, dass Daten nicht vorab in einem definierten Schema strukturiert werden müssen, sondern erst bei der Leseoperation direkt nach dem Zugriff auf die Daten. Im Gegensatz zum Schema on Write Verfahren, bei dem Daten vor dem Schreibvorgang in ein festes Schema umgewandelt werden müssen, können Daten hier einfach in einen Data Lake oder Data Pool unkompliziert abgelegt werden, auch sehr verschiedenartige strukturierte und unstrukturierte Daten und in einer großen Masse. Ein Data Scientist kann sich dann aus diesen Daten bedienen und muss sie nicht extra und langwierig einfordern.
Das Data Lakehouse als Lösung
Dank des Einsatzes eines Data Lakehouse können Unternehmen eine hocheffektive Datenverfügbarkeit erreichen und dabei ihre Dateninfrastruktur in ihrer Effizienz optimieren und dabei Kosten senken, da sie nicht mehrere separate Systeme für Datenspeicherung, Datenintegration und Datenanalyse verwalten müssen. Ein Data Lakehouse leitet sich aus den Konzepten des Data Warehouse und des Data Lake ab, bietet eine einzige Plattform, die alle diese Funktionen in einem System integriert.
Data Warehouse – Der sortierte Aktenschrank
Ein Data Warehouse ist eine zentrale Datenbank, die speziell für die Analyse und Berichterstattung konzipiert ist. Diese Zentralität wird in ihrer Bedeutung mit dem Anspruch unterstrichen, in Sachen Daten und Informationen eine Single Source of Truth für ein Unternehmen bzw. für eine bestimmte Organisation zu sein.
Es handelt sich um eine spezielle Art von Datenbank, die Daten aus verschiedenen Quellen sammelt, integriert und bereinigt, um eine umfassende und konsistente Sicht auf das Unternehmen zu ermöglichen. Ein Data Warehouse unterscheidet sich von traditionellen Datenbanken durch seine Fähigkeit, Daten aus verschiedenen Quellen zusammenzuführen und in einer gemeinsamen Struktur zu speichern. Daten können aus internen und externen Quellen wie ERP-Systemen, CRM-Systemen, Log-Dateien und anderen Quellen stammen.
Ein weiteres Merkmal von Data Warehouses ist, dass sie in der Regel für die Entscheidungsunterstützung und Berichterstattung verwendet werden. Die Daten im Data Warehouse werden für die Analyse und Berichterstattung aufbereitet und in aussagekräftige Informationen und Berichte umgewandelt.
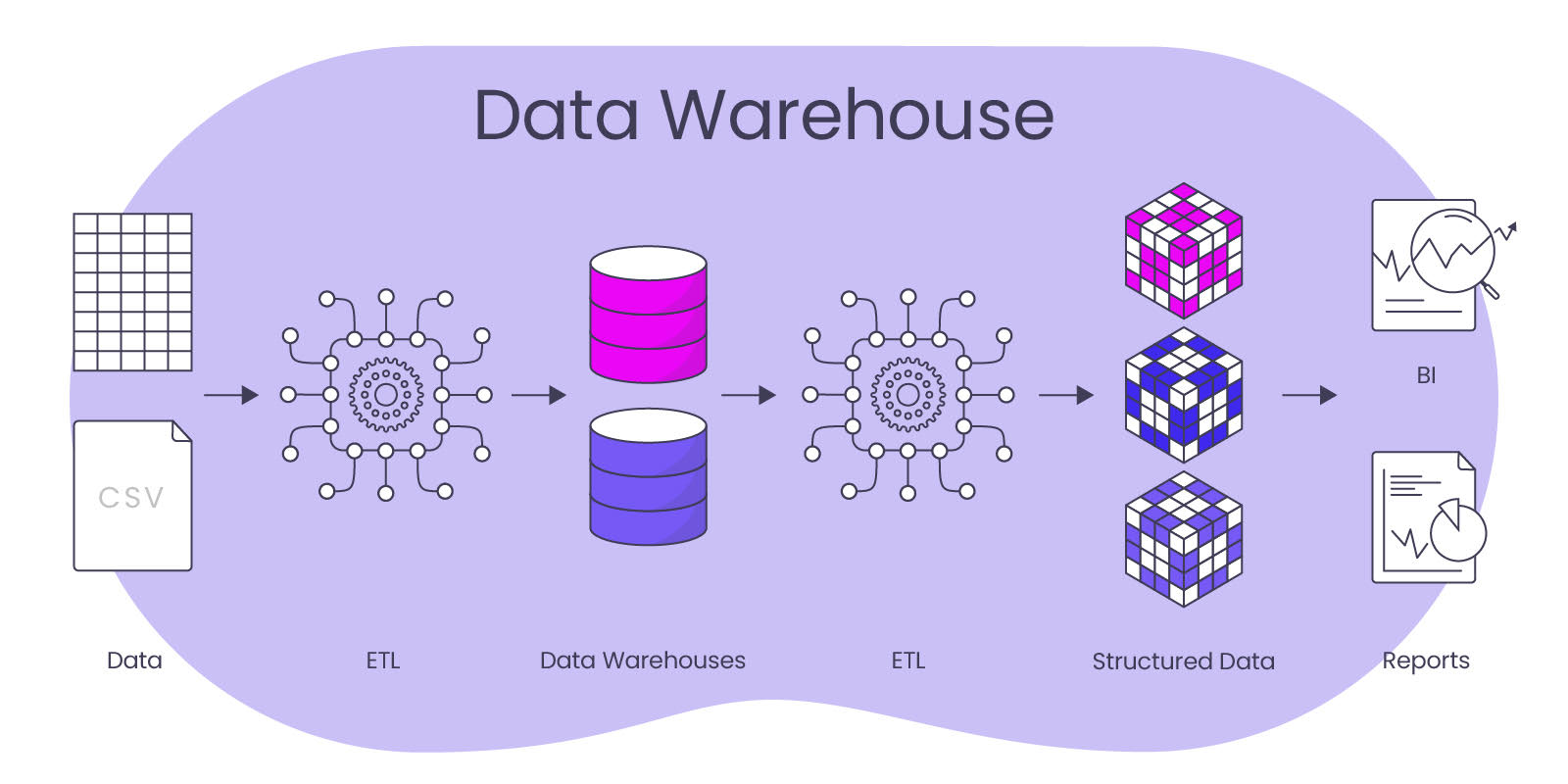
Schema on Write (Formatierung beim Schreibvorgang) ist ein Ansatz für die Verarbeitung von Daten in einer Datenbank oder einem Data-Warehouse. Es bezieht sich darauf, dass Daten bei der Eingabe in das System in einem bestimmten Schema oder Format strukturiert werden müssen. Daten werden in einem Data Warehouse nicht nur bereinigt und konsolidiert, sondern auch in für das Reporting freundliche Datenmodelle transformiert, wie beispielsweise das Sternen-Schema (Star Schema). Daraus leitet sich der Nachteil ab, dass Data Warehouses teuer und zeitaufwendig sein können, den Daten müssen sorgfältig bereinigt und integriert werden, um sicherzustellen, dass sie für die konsumierenden Applikationen (u.a. BI-Tools für Reporting) konsistent und aussagekräftig sind.
Data Lake – Der Allesspeicher
Im Data Lake geschieht das Gegenteil gegenüber Data Warehouse, denn in ihnen werden Daten in ihrer ursprünglichen, nicht-strukturierten Form gespeichert. Ein Data Lake ist eine skalierbare Datenplattform, auf der strukturierte und unstrukturierte Daten gespeichert, verwaltet und analysiert werden können. Im Gegensatz zu traditionellen Datenbanken, die in der Regel auf ein bestimmtes Schema beschränkt sind, ist ein Data Lake flexibler und kann große Mengen von Daten unterschiedlicher Art und Quelle speichern.
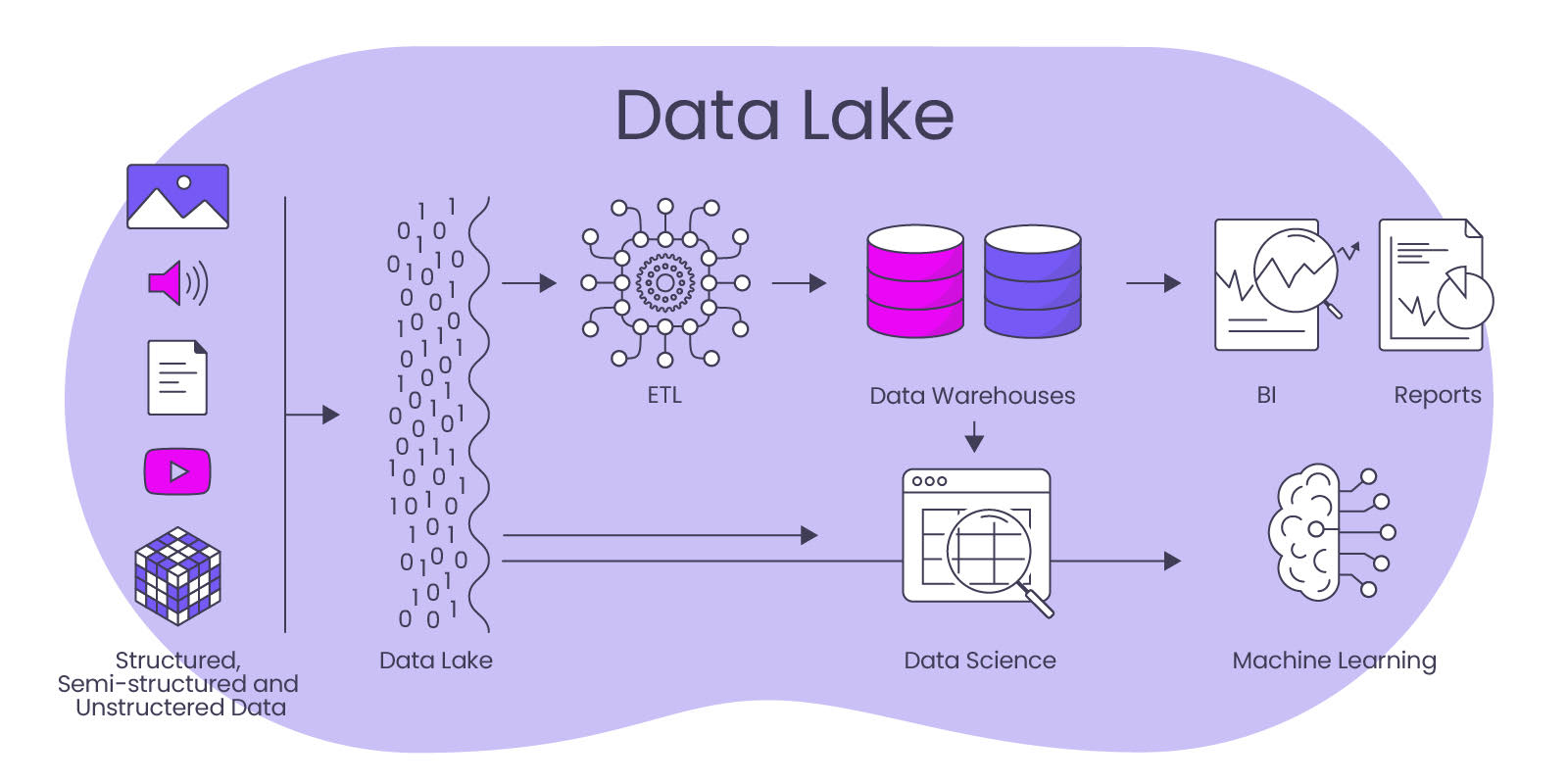
Data Lakes werden selten alleinstehend verwendet, sondern sind Teil einer Datenstrategie, die auch ein Data Warehouse vorsieht, das sich zumindest teilweise aus dem Data Lake nähert. Der Data Lake ergänzt die Gesamt-Datenarchitektur um Archive von Datenhistorien (z. B. für das Training von KI), denn mit dem Ansatz des Schema on Read (Formatierung beim Lesen) werden Daten in ihrer ursprünglichen, nicht-strukturierten Form in einem Data Lake gespeichert. Daten können also einfach und ohne viel Organisation im Lake abgelegt werden. Diese Daten können in verschiedenen Formaten wie Text, JSON, CSV oder anderen Formaten vorliegen. Ein Schema wird erst auf die Daten angewendet, wenn sie aus dem Data Lake gelesen werden, um sie in eine analytische Engine oder ein anderes Verarbeitungssystem zu laden.
Im Gegensatz dazu steht das Schema on Write -Verfahren, wie es für das Data Warehouse gilt, müssen Daten vor dem Schreibvorgang nicht in ein festes Schema umgewandelt werden.
Schema on Read bietet mehr Flexibilität insbesondere für einen Data Scientist, da es eine einfachere Integration von unterschiedlichen Datenquellen und -formaten ermöglicht. Es ist besonders vorteilhaft in Umgebungen mit großen und heterogenen Datenmengen, da es schnelle Verarbeitung und Analyse von Daten in unterschiedlichen Formaten ermöglicht. Ein potenzieller Nachteil von Schema on Read besteht jedoch darin, dass konsistente Datenqualität kaum sicherzustellen ist, da es keine einheitlichen Datenstrukturen und -formate gibt. Eine gründliche Datenbereinigung und -transformation ist daher dann spätestens unmittelbar vor der Analyse notwendig, um Daten für eine aussagekräftige Analyse vorzubereiten.
Data Lakehouse – Der State of the Art Alleskönner
Ein Data Lakehouse ist ein neues Konzept für die Datenverarbeitung, das eine prozessintegrative Kombination aus Data Warehouse und Data Lake darstellt. Es ist ein Ansatz, der die Flexibilität und Skalierbarkeit eines Data Lakes mit der Strukturierung und Integration von Daten in einem Data Warehouse verbindet.
Ein Data Lakehouse speichert Daten in ihrem nativen Format, ähnlich wie ein Data Lake. Die Daten werden in Rohform gespeichert und dann mit Hilfe von strukturierten Metadaten in eine Tabellenform transformiert. Im Gegensatz zu einem Data Lake werden jedoch als besonders relevant identifizierte Daten strukturell aufgearbeitet, ähnlich wie bei einem Data Warehouse. Dies bedeutet, dass ein Data Lakehouse sowohl strukturierte als auch unstrukturierte Daten speichern, durchsuchen, verarbeiten und verknüpfen kann.
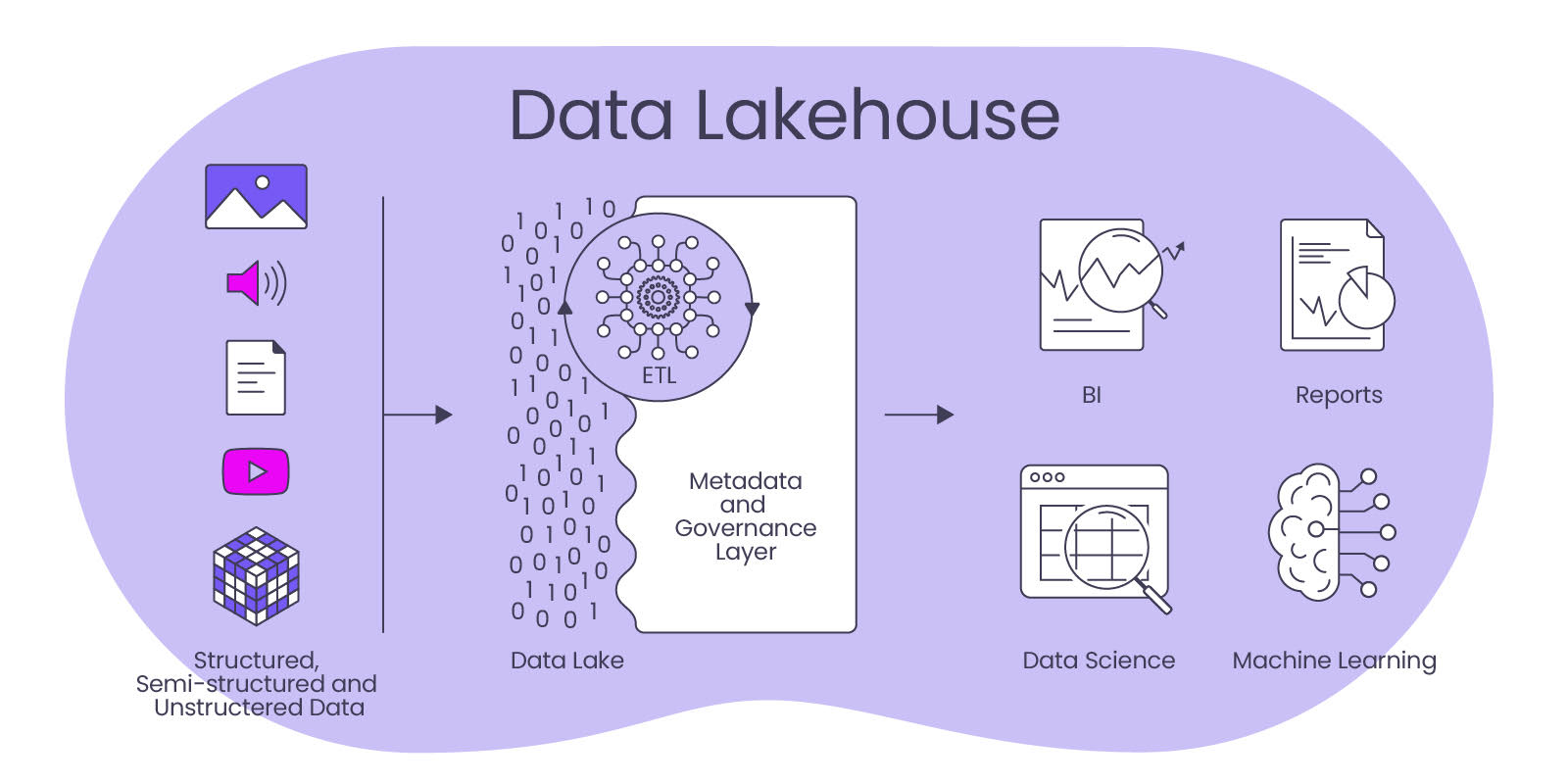
Ein wichtiger Vorteil eines Data Lakehouse ist, dass sie sowohl strukturierte als auch unstrukturierte Daten integrieren und verarbeiten können, was eine höhere Flexibilität und Skalierbarkeit für vielseitige Anwendungen ermöglicht und eine hohe Zukunftssicherheit bringt. Durch die Kombination von Data Lake und Data Warehouse Technologien können Unternehmen schneller und kosteneffektiver auf ihre Daten zugreifen und sie verarbeiten. Diese Architektur ist besonders für datenintensive Anwendungen und die Analyse von Big Data geeignet, ist dabei jedoch stets die zentrale Datenquelle für alle analytischen Applikationen (BI, Process Mining, Data Science, AI) sowie für sich anschließende operative IT-Systeme.
Ein Data Lakehouse ermöglicht es Unternehmen demnach, schneller und effizienter auf Daten zugreifen und diese verarbeiten können. Dadurch können sie ihre Daten als Produktionsfaktor effektiver nutzen und schneller Erkenntnisse und Einsichten gewinnen, die zur Verbesserung von Geschäftsprozessen beitragen.
![]() DATANOMIQ ist der herstellerunabhängige Beratungs- und Service-Partner für Business Intelligence, Process Mining und Data Science. Wir erschließen die vielfältigen Möglichkeiten durch Big Data und künstliche Intelligenz erstmalig in allen Bereichen der Wertschöpfungskette. Dabei setzen wir auf die besten Köpfe und das umfassendste Methoden- und Technologieportfolio für die Nutzung von Daten zur Geschäftsoptimierung.
DATANOMIQ ist der herstellerunabhängige Beratungs- und Service-Partner für Business Intelligence, Process Mining und Data Science. Wir erschließen die vielfältigen Möglichkeiten durch Big Data und künstliche Intelligenz erstmalig in allen Bereichen der Wertschöpfungskette. Dabei setzen wir auf die besten Köpfe und das umfassendste Methoden- und Technologieportfolio für die Nutzung von Daten zur Geschäftsoptimierung.


Pingback: Big Data - Das Versprechen wurde eingelöst - Data Science Blog
Pingback: Big Data - Das Versprechen wurde eingelöst - Data Science Blog (German only)
Pingback: Process Mining - Ist Celonis wirklich so gut? Ein Praxisbericht. - Data Science Blog