Big Data Analytics unterscheidet sich grundlegend von der klassischen Datenverarbeitung. Die Anlieferung der Daten in einem Data Engineering Prozess für Anwendungen der Business Intelligence, Process Mining oder Data Science / KI ist ein zentraler Aspekt einer jeden Cloud Data Platform. Zwei Architektur-Konzepte geistern durch die Big Data Welt und Unternehmen, die ihre Big Data Plattform gerade erst errichten – oder reorganisieren – möchten, sollten sich einmal die Frage stellen: Lambda- oder Kappa-Architektur?
Lambda – Architektur
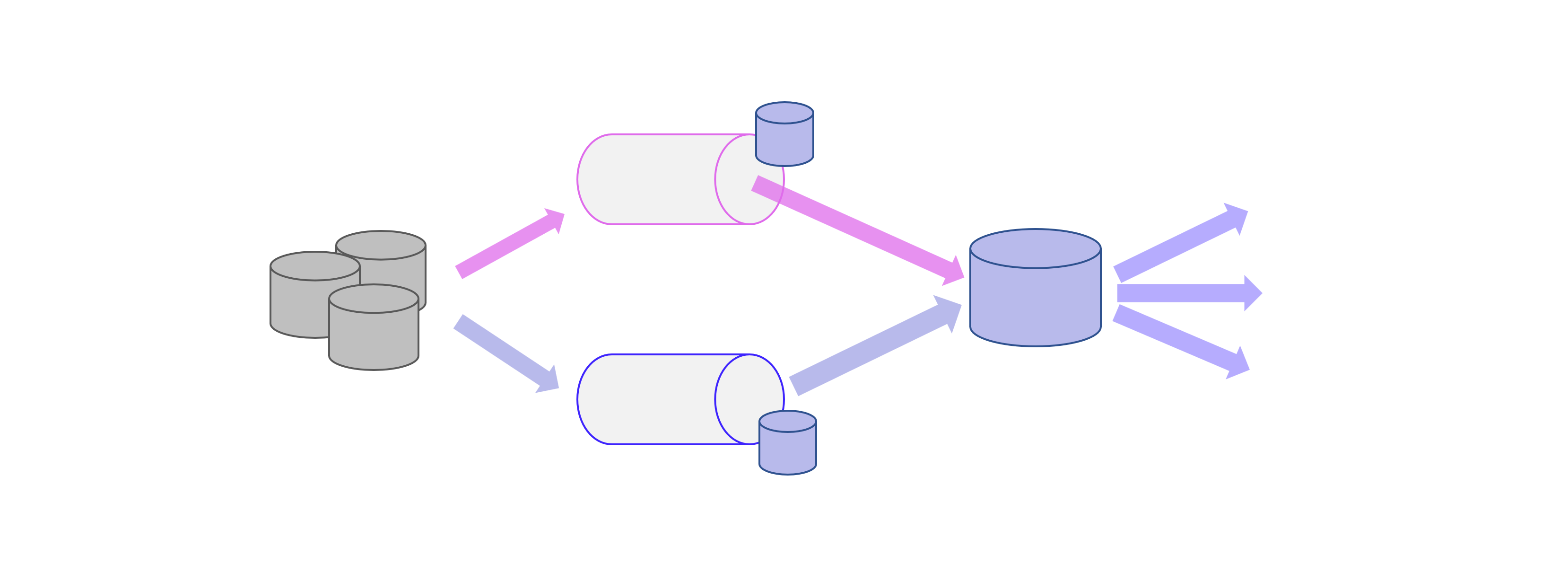
Die Lambdaarchitektur wurde 2011 vorgestellt, damals war Big Data noch das große Trendthema, das ganze Konferenzen füllte. Diese Architektur ist zwar die ältere von beiden, eigentlich aber die umfassendere Architektur mit einer Batch-Schicht, einer Speed-Schicht (auch als Stream-Schicht bezeichnet) und die Serving-Schicht.
Die Batch-Schicht verarbeitet die vollständigen Daten und ermöglicht es dem System somit, die genauesten Ergebnisse zu erzielen. Die Ergebnisse werden jedoch durch hohe Latenzzeiten auf Grund des Batch-Ladens als Datenstapel erkauft. Dafür kann die Batch-Schicht auch komplexere Berechnungen durchführen, denn es eilt ja nicht. Die Batch-Schicht speichert die Rohdaten, sobald sie eintreffen und filtert die Daten für die nachführenden Applikationen.
Batch-Läufe werden für jene Daten vorgesehen, die zeitlich nicht kritisch sind und bevorzugt täglich oder wöchentlich als Update (Incremental Load) geladen werden müssen. Ferner werden Batch-Läufe notwendig, sollten Daten komplett neu migriert oder überschrieben werden (Full Load).
Die Speed-Schicht erzeugt Ergebnisse mit geringer Latenz und nahezu in Echtzeit. Sie wird zur Berechnung der Echtzeitansichten verwendet, die die Batch-Ansichten ergänzen. Die Geschwindigkeitsebene empfängt die ankommenden Daten und führt inkrementelle Aktualisierungen der Ergebnisse der Batch-Ebene durch. Dank der inkrementelle Abzugslogik, die in der Speed-Schicht implementiert sind, werden die Berechnungskosten erheblich reduziert.
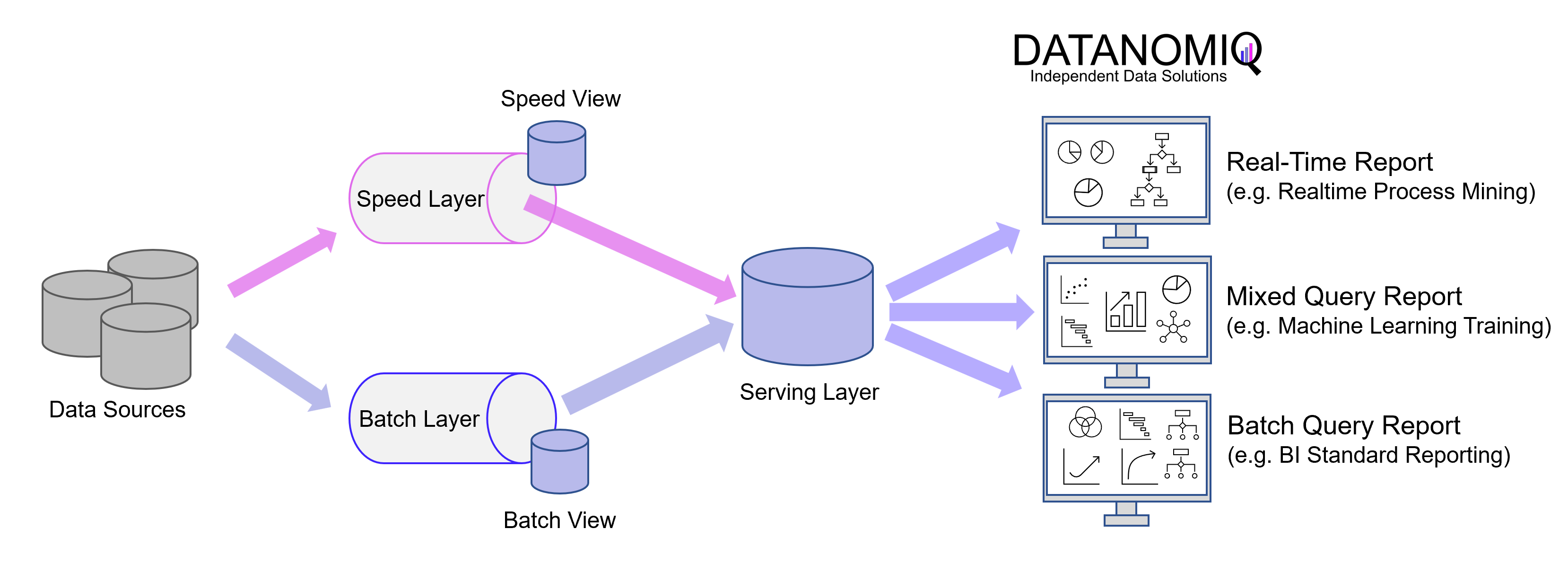
Die Batch-Ansichten können mit komplexeren oder teureren Regeln verarbeitet werden und weisen daher in der Regel langfristig eine bessere Datenqualität und geringere Verzerrungen auf, während die Echtzeit-Ansichten einen aktuellen Zugang zu den aktuellsten Daten ermöglichen.
Schließlich ermöglicht die Serving-Schicht verschiedene Abfragen der von der Batch- und der Speed-Schicht gesendeten Daten. Die Ergebnisse der Batch-Schicht in Form von Batch-Ansichten und der Speed-Schicht in Form von Near-Real-Time-Ansichten werden an die Serving-Schicht weitergeleitet, die diese Daten verwendet, um die anstehenden Abfragen für das Standard Reporting und für Ad-hoc-Analytics zu ermöglichen.
Die Lambda-Architektur kann ein Gleichgewicht zwischen Geschwindigkeit, Zuverlässigkeit und Skalierbarkeit schaffen. Allerdings, obwohl die Batch-Schicht und der Echtzeit-Stream mit unterschiedlichen Szenarien konfrontiert sind, ist ihre interne Verarbeitungslogik oft im Kern dieselbe, so dass Aufwände für Entwicklung und Wartung nicht zu unterschätzen sind.
Kappa – Architektur
Die Kappa-Architektur wurde von Jay Kreps im Jahr 2014 beschrieben und löst den redundanten Teil der Lambda-Architektur auf, indem sie ganz auf den Batch-Teil verzichtet. Die Kappa-Architektur reduziert die architektonische Komplexität durch Wegfall zwei parallel laufender Pipelines. In der Kappa-Architektur bleibt nur die Geschwindigkeitsschicht in Form einer event-basierten Streaming-Pipeline. Der Kerngedanke besteht darin, die Datenverarbeitung in Echtzeit und die kontinuierliche Wiederverarbeitung von Daten mit einem einzigen Stream-Processing-Engine zu bewältigen und eine mehrschichtige Lambda-Architektur zu vermeiden, während gleichzeitig die Qualität des Processing der Daten eingehalten wird.
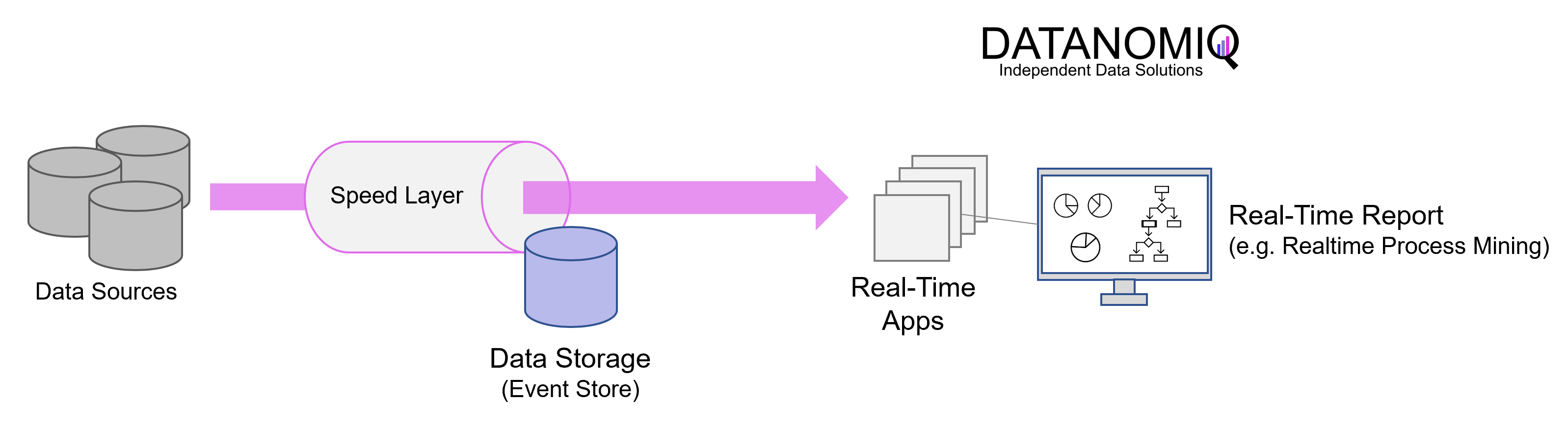
In der Praxis wird diese Architektur in der Regel mit Apache Kafka (oder auf Kafka basierende Tools) umgesetzt. Anwendungen können direkt in Kafka (oder einem alternativen Tool der Kategorie Nachrichtenwarteschlange) lesen und schreiben. Bei vorhandenen Ereignisquellen werden Listener verwendet, um Schreibvorgänge direkt aus Datenbankprotokollen (oder entsprechenden Datenspeichern) zu streamen, wodurch die Notwendigkeit einer Stapelverarbeitung während des Eingangs entfällt und weniger Ressourcen benötigt werden.
Da jeder Datenpunkt in Ihrem Unternehmen als Streaming-Ereignis behandelt wird, können Sie zu jedem beliebigen Zeitpunkt eine „Zeitreise“ unternehmen und den Zustand aller Daten in Ihrem Unternehmen einsehen. Abfragen müssen nur an einem einzigen Speicherort durchgeführt werden, anstatt Batch- und Geschwindigkeitsansichten vergleichen zu müssen.
Die Schattenseite dieser Architektur liegt vor allem darin, dass die Daten in einem Stream verarbeitet werden müssen und es hierbei zu Herausforderungen kommt, z. B. der Umgang mit doppelten Ereignissen, Querverweise auf Ereignisse oder die Aufrechterhaltung der richtigen Reihenfolge der Vorgänge. Da die Stapelverarbeitung sich hier mehr Zeit lassen und mehrere Datensätze rückblickend selbst konsolidieren kann, bleiben diese Herausforderungen nach Kappa bestehen. Architekturen nach diesem Konzept sind daher schwieriger zu realisieren als jene nach dem Lambda-Konzept, auch wenn letztere auf der Architektur-Skizze übersichtlicher aussehen mag.
Sollten die Anwendungsfälle für Event Streaming bzw. Realtime Processing überwiegen, könnte die Kappa-Architektur sinnvoll sein, da es nur diese eine ETL-Platform zu entwickeln und warten gibt. Die Kappa-Architektur kann für die Entwicklung von Datensystemen verwendet werden, die online lernfähig sind und daher keine Batch-Schicht benötigen. Die Reihenfolge der Ereignisse und Abfragen ist nicht vorgegeben und wird nur in späteren Schritten gemäß Business Logik hergestellt, denn hier steht die Geschwindigkeit im Vordergrund.
Anwendungsfälle – Wann bitte welche Architektur?
Zunächst einmal ist Kappa kein Ersatz für Lambda, da einige Anwendungsfälle, die mit der Lambda-Architektur bereitgestellt werden, nicht migriert werden können. Aufwendige Datenprozesse und eine stets vollständige Datenbereitstellung lässt sich mit der Lambda-Architektur leichter realisieren als mit dem reinen Event Processing nach Kappa. Die Meisten Data Lakehouse Systeme basieren daher auf der Lambda-Architektur und modellieren ihre Daten z. B. in einem Galaxy Star Schema, in normalisierten Modellen und/oder nach dem Data Vault Konzept.
Anforderungen, die klar für Lambda sprechen
- Wenn Daten auch ad-hoc auf quasi unveränderlichen, qualitätsgesicherten Datenbeständen erfolgen sollen bzw. wenn der Fokus der Datenbasis auf Datenqualität und die Vermeidung von Widersprüchlichkeit liegt.
- Wenn zwar schnelle Antworten erforderlich sind, das System aber dennoch verschiedene Aktualisierungszyklen verarbeiten können.
Anforderungen, die klar für Kappa sprechen:
- Wenn die auf die Echtzeitdaten und die historischen Daten angewandten Algorithmen identisch sind.
- Wenn das Analyse-System online lernfähig ist und daher keine Batch-Schicht benötigt. Siehe auch: Machine Leaning – Online vs Offline Learning.
- Die Reihenfolge der Ereignisse und Abfragen spielt keine Rolle, jedoch das Stream-Processing-Plattformen zu jeder Zeit sofort Daten mit der Datenbank austauschen können.
Wenn Sie eine Architektur benötigen, die bei der Aktualisierung des Data Lakehouses zuverlässiger und beim Trainieren der Modelle für maschinelles Lernen effizienter ist, um Ereignisse zuverlässig vorherzusagen, dann sollten Sie die Lambda-Architektur verwenden, da sie die Vorteile sowohl der Batch-Schicht als auch der Speed-Schicht nutzt, um wenige Fehler und Geschwindigkeit zu gewährleisten.
Wenn Sie hingegen eine Big-Data-Architektur schlankerer Aufstellung bereitstellen möchten und eine effektive Verarbeitung einzigartiger, kontinuierlich auftretender Ereignisse benötigen (z. B. für die Datenversorgung vieler mobiler Anwendungen), dann wählen Sie die Kappa-Architektur für Ihre Echtzeit-Datenverarbeitungsanforderungen.
![]() DATANOMIQ ist der herstellerunabhängige Beratungs- und Service-Partner für Business Intelligence, Process Mining und Data Science. Wir erschließen die vielfältigen Möglichkeiten durch Big Data und künstliche Intelligenz erstmalig in allen Bereichen der Wertschöpfungskette. Dabei setzen wir auf die besten Köpfe und das umfassendste Methoden- und Technologieportfolio für die Nutzung von Daten zur Geschäftsoptimierung.
DATANOMIQ ist der herstellerunabhängige Beratungs- und Service-Partner für Business Intelligence, Process Mining und Data Science. Wir erschließen die vielfältigen Möglichkeiten durch Big Data und künstliche Intelligenz erstmalig in allen Bereichen der Wertschöpfungskette. Dabei setzen wir auf die besten Köpfe und das umfassendste Methoden- und Technologieportfolio für die Nutzung von Daten zur Geschäftsoptimierung.