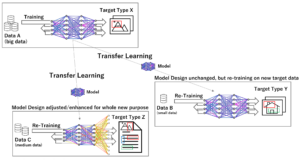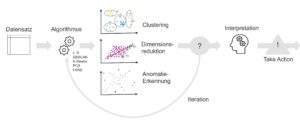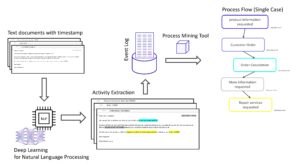
Unternehmen nutzen Business Intelligence (BI), Data Science und Process Mining, um Daten für eine bessere Entscheidungsfindung zu nutzen, die betriebliche Effizienz zu verbessern und einen Wettbewerbsvorteil zu erzielen. BI bietet Datenanalyse und Leistungsüberwachung in Echtzeit, während Data Science mit Data Mining ein tiefes Eintauchen in Datenabhängigkeiten ermöglicht und die Entscheidungsfindung mit prädiktiven Analysen und personalisierten Kundenerfahrungen automatisiert. Process Mining bietet Prozesstransparenz, Einblicke in die Compliance und Prozessoptimierung. Die Integration dieser Technologien hilft Unternehmen, Daten für Wachstum und Effizienz nutzbar zu machen.
Gesamtheitlicher Ansätze sind nachhaltiger für Unternehmen
Obwohl all diese analytischen Konzepte zusammenwachsen, werden sie oft noch als getrennte Anwendungen betrachtet. In einer großen Organisation stellt sich oft die Frage nach der Verantwortung. Wenn diese Verantwortung nicht zentral geregelt ist, könnte Data Mesh eine Lösung sein.
Data Mesh ist ein architektonischer Ansatz für die Verwaltung von Daten in Organisationen. Er befürwortet die Dezentralisierung des Dateneigentums (Data Ownership) auf bereichsorientierte Teams. Jedes Team übernimmt die Verantwortung für seine Datenprodukte, und es wird eine selbst-verwaltete Dateninfrastruktur geschaffen. Dies ermöglicht Skalierbarkeit, Agilität und verbesserte Datenqualität und fördert gleichzeitig die Demokratisierung von Daten.
Im Kontext eines Data Mesh bezieht sich ein Datenprodukt auf einen wertvollen Datensatz oder einen Datenservice, der von einem bestimmten bereichsorientierten Team innerhalb einer Organisation verwaltet wird und ihm gehört. Es ist eines der Schlüsselkonzepte in der Data Mesh-Architektur, in der Dateneigentum und -verantwortung auf verschiedene Domänen-Teams verteilt sind und nicht in einem einzigen Datenteam zentralisiert werden.
Ein Datenprodukt (Data Product) kann verschiedene Formen annehmen, je nach den Anforderungen des Bereichs und den von ihm verwalteten Daten. Dabei kann es sich um einen kuratierten Datensatz, ein Modell für maschinelles Lernen, eine API, die Daten offenlegt, einen Echtzeit-Datenstrom, ein Dashboard zur Datenvisualisierung oder ein anderes datenbezogenes Asset handeln, das einen Mehrwert für das Unternehmen darstellt.
Für eine erfolgreiche Implementierung müssen jedoch kulturelle, Governance- und technologische Aspekte berücksichtigt werden. Einer dieser Aspekte ist die Cloud-Architektur für die Realisierung von Data Mesh.
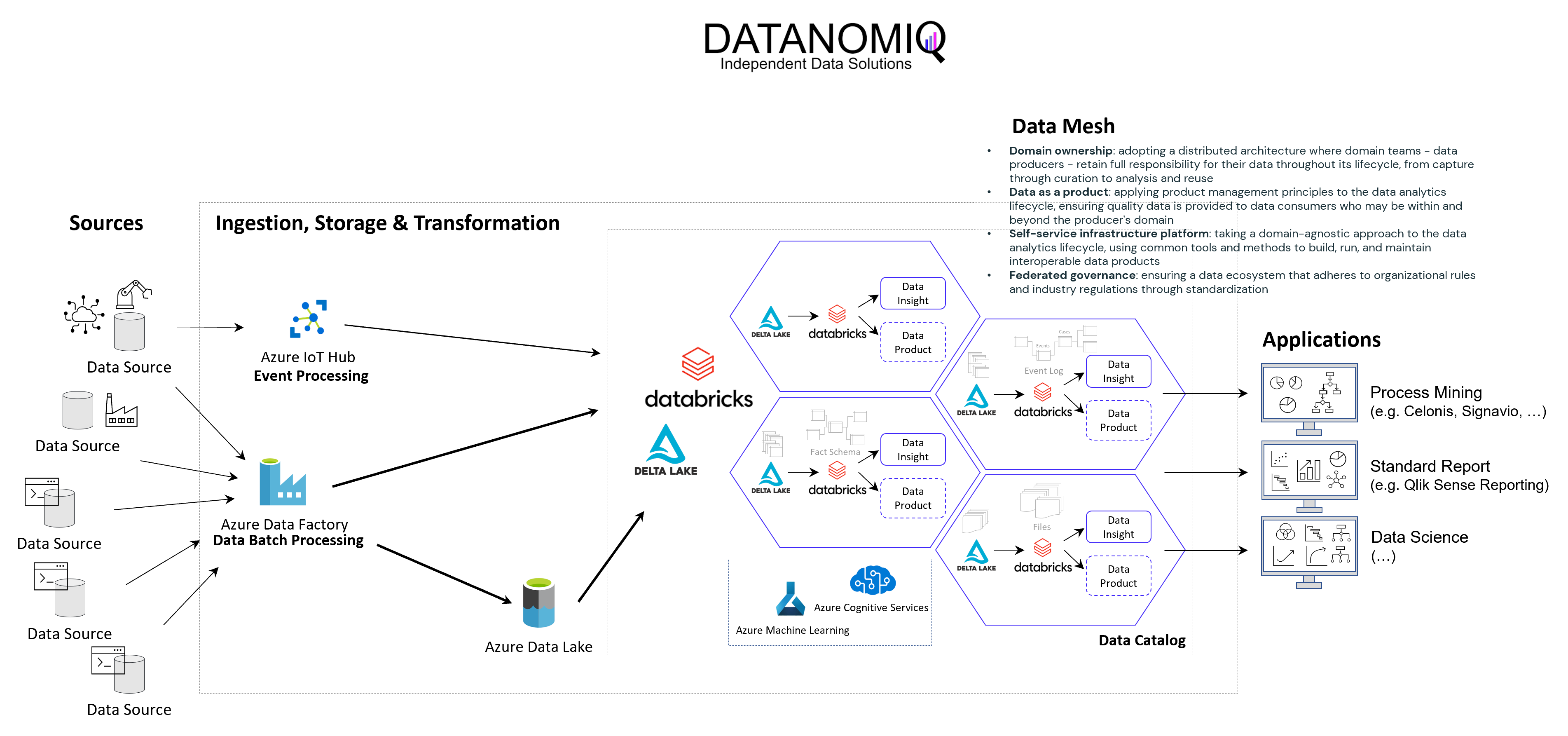
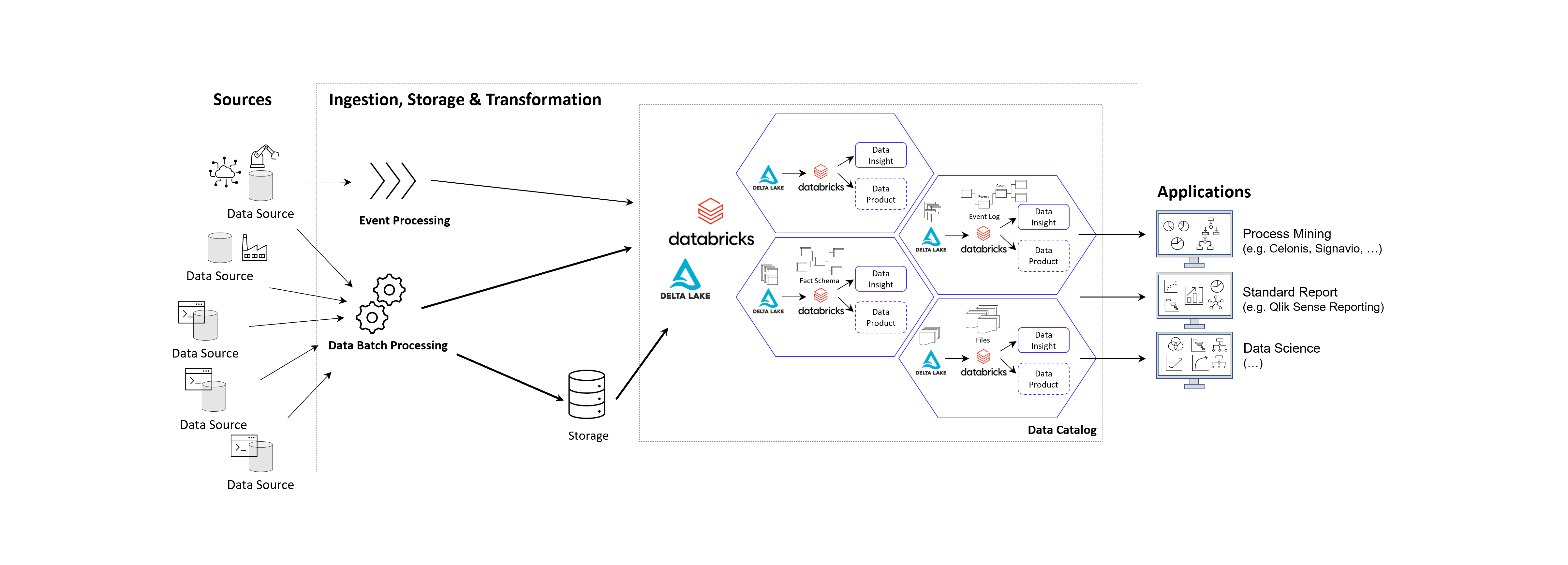
Die obige Abbildung zeigt ein Beispiel für ein von DATANOMIQ erstelltes und verwaltetes Data Mesh für eine Organisation, die Datensätze aus verschiedenen Datenquellen (ERP, CRM, DMS, IoT,…) nutzt und wiederverwendet, um die Daten sowie geeignete Datenmodelle als Datenprodukte für Anwendungen von Data Science, Process Mining (Celonis, UiPath, Signavio & more) und Business Intelligence (Tableau, Power BI, Qlik & more) bereitzustellen.
Mit dem Konzept des Data Mesh können Sie einmalig auf alle organisationsinternen und -externen Datenquellen zugreifen und die Daten als verschiedene Datenmodelle für alle Ihre analytischen Anwendungen bereitstellen. Die Datenmodelle werden als Datenprodukte mit definiertem Wert, Kosten und Verantwortlichkeiten betrachtet. Jede Anwendung hat ihr eigenes Datenmodell. Während Data-Science-Anwendungen über mehr Rohdaten verfügen, erhalten BI-Anwendungen ihre gut vorbereiteten Star-Schema-Datenmodelle und Process-Mining-Anwendungen erhalten normalisierte Event-Log-Datenmodelle. Mit Hilfe von Data Sharing (in Databricks: Delta Sharing) können Datenprodukte oder einzelne Datensätze durch Anwendungen und Eigentümer gemeinsam genutzt sowie über Datenkatloge (Data Catalog) hinsichtlich der Zugriffe verwaltet werden.
![]() DATANOMIQ ist der herstellerunabhängige Beratungs- und Service-Partner für Business Intelligence, Process Mining und Data Science. Wir erschließen die vielfältigen Möglichkeiten durch Big Data und künstliche Intelligenz erstmalig in allen Bereichen der Wertschöpfungskette. Dabei setzen wir auf die besten Köpfe und das umfassendste Methoden- und Technologieportfolio für die Nutzung von Daten zur Geschäftsoptimierung.
DATANOMIQ ist der herstellerunabhängige Beratungs- und Service-Partner für Business Intelligence, Process Mining und Data Science. Wir erschließen die vielfältigen Möglichkeiten durch Big Data und künstliche Intelligenz erstmalig in allen Bereichen der Wertschöpfungskette. Dabei setzen wir auf die besten Köpfe und das umfassendste Methoden- und Technologieportfolio für die Nutzung von Daten zur Geschäftsoptimierung.