

Jurek Dörner wird neuer COO von DATANOMIQ
Stärkung der operativen Führung für Data Engineering, BI und Process Mining DATANOMIQ gibt die Ernennung von Jurek Dörner zum Chief Operating Officer (COO) bekannt. In seiner neuen Rolle übernimmt...
Weiter lesen
Webinar: Daten & KI in der Industrie
Künstliche Intelligenz und Datenanalyse sind in der Industrie angekommen. Doch wie gelingt der Sprung von der Theorie zur praktischen Anwendung? Die Antwort mit Perspektiven und Anwendungsfällen gebe ich zusammen...
Weiter lesen
Der Gartner Magic Quadrant 2025 für Process Mining: Einblicke und Reflexionen
Der Gartner Magic Quadrant 2025 für Process Mining wurde soeben veröffentlicht – basierend auf Daten bis Dezember 2024. Wie erwartet entwickelt sich die Landschaft weiter, doch einige bekannte Namen...
Weiter lesen
KI im Process Mining – Use Cases & Value
Traditionelles Process Mining extrahiert aus Event Logs wertvolle Einblicke in reale Prozesse – unabhängig davon, was in Dokumentationen oder Soll-Prozessmodellen steht. KI hebt diese Fähigkeit auf ein neues Niveau,...
Weiter lesen
VWI e.V. Podcast – Benjamin Aunkofer über Karriere mit Daten & KI
🎙️In der 14. Folge des VWI Podcasts des Vereins deutscher Wirtschaftsingenieure (VWI) e.V. begrüßt Moderator Jan Rupprecht einen unseren Gründer und Geschäftsführer, Benjamin Aunkofer. Er ist selbst Wirtschaftsingenieur, Software...
Weiter lesen
Daten & KI in der Produktion – Podcast
Wie können datengetriebene Prozessanalysen und Künstliche Intelligenz die Industrie 4.0 revolutionieren? Der DATANOMIQ Gründer, Benjamin Aunkofer, spricht in einer Folge im Podcast "Fabrik der Zukunft" über die Möglichkeiten der...
Weiter lesen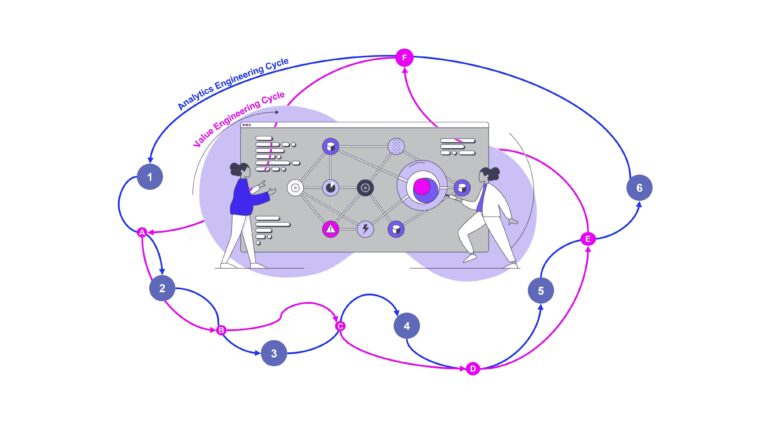
Process Mining braucht Value Engineering
Geht es beim Process Mining wirklich immer um die Schaffung von Prozesstransparenz? Ja, natürlich! Aber nur, wenn es richtig angegangen wird. Dann gibt es aber auch viele andere Mehrwerte,...
Weiter lesen
Grundlagen der KI und Quick Wins für die Wirtschaftsprüfung
Benjamin Aunkofer, Gründer der DATANOMIQ GmbH, führt am 13.11.2024 von 16:15 Uhr bis 18:15 Uhr in die Grundlagen der KI und Quick Wins in der Jahresabschlussprüfung (Wirtschaftsprüfung) ein. Künstliche...
Weiter lesen
Data Assessment für Ihre Ogranisation
𝗘𝗻𝘁𝗳𝗲𝘀𝘀𝗲𝗹𝗻 𝗦𝗶𝗲 𝗱𝗮𝘀 𝗣𝗼𝘁𝗲𝗻𝘇𝗶𝗮𝗹 𝗜𝗵𝗿𝗲𝗿 𝗗𝗮𝘁𝗲𝗻 𝗺𝗶𝘁 𝗲𝗶𝗻𝗲𝗺 𝘂𝗺𝗳𝗮𝘀𝘀𝗲𝗻𝗱𝗲𝗻 𝗗𝗮𝘁𝗮 𝗔𝘀𝘀𝗲𝘀𝘀𝗺𝗲𝗻𝘁! Die Fähigkeit, Daten und Prozesse effektiv zu bewerten, ist entscheidend für den Geschäftserfolg. Ein Data Assessment zeigt, wie...
Weiter lesenDeprecated: preg_replace(): Passing null to parameter #3 ($subject) of type array|string is deprecated in /var/www/datanomiq/wp-includes/kses.php on line 1807