
Realisieren Sie Ihre Data Mesh Architektur in der Cloud und mit den Tools Ihrer Wahl
Big Data Cloud Architecture
Unternehmen nutzen Business Intelligence (BI), Data Science und Process Mining, um Daten für eine bessere Entscheidungsfindung zu nutzen, die betriebliche Effizienz zu verbessern und einen Wettbewerbsvorteil zu erzielen.
DATANOMIQ macht Daten aus allen organisatorischen sowie aus unternehmensexternen Quellen zentral in einer Cloud Data Architecture mit dem Organisationsentwurf eines Data Mesh für alle analytischen Applikationen nutzbar.

Data Mesh auf Ihrer Cloud
Egal ob Sie auf der Microsoft Azure Cloud, Google Cloud (GCP), Amazon Cloud (AWS) oder der SAP Cloud (Datasphere) arbeiten, wir konzipieren und realisieren Ihre Data Mesh Organisation für Sie auf dieser und sorgen für die zentral-dezentrale Belieferung aller analytischen Applikationen mit Datenmodellen.
Zentralisiert wird dabei die generelle Datenbereitstellung (Data Ingestion) aus den Quellsystemen und die rudimentäre Datenaufbereitung und -fusionierung. Dezentralisiert wird hingegen die applikations- und anwendungsfallspezifische Endmodellierung, beispielsweise der Kategorien BI Reporting (Fakten + Dimensionen), Process Mining (Event Logs) oder Data Science / Künstliche Intelligenz (Datenhistorien).
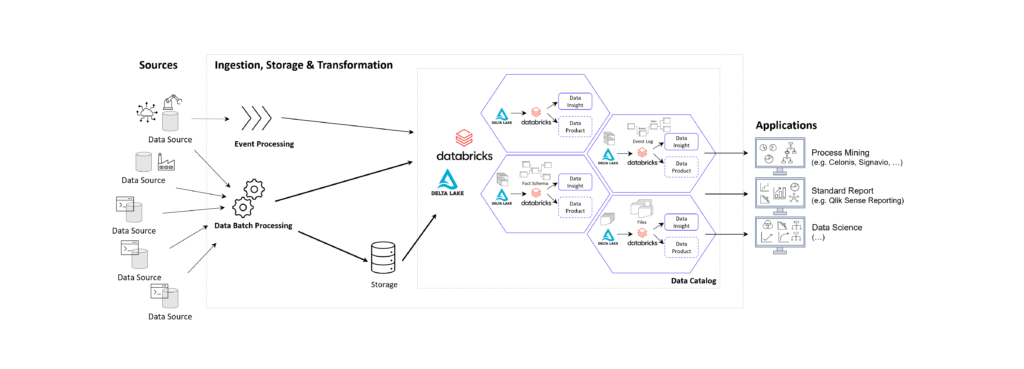
Data Products
Ein Datenprodukt (Data Product) ist der vielfältige Fokus des Data Mesh und kann verschiedene Formen annehmen, je nach den Anforderungen des Bereichs und den von ihm verwalteten Daten. Dabei kann es sich um einen kuratierten Datensatz, ein Modell für maschinelles Lernen, eine API, die Daten offenlegt, einen Echtzeit-Datenstrom, ein Dashboard zur Datenvisualisierung oder ein anderes datenbezogenes Asset handeln, das einen Mehrwert für das Unternehmen darstellt.
Data Ownership
Data Mesh ist ein architektonischer Ansatz für die Verwaltung von Daten in Organisationen. Er befürwortet die Dezentralisierung des Dateneigentums (Data Ownership) auf bereichsorientierte Teams. Jedes Team übernimmt die Verantwortung für seine Datenprodukte, und es wird eine selbst-verwaltete Dateninfrastruktur geschaffen. Dies ermöglicht Skalierbarkeit, Agilität und verbesserte Datenqualität und fördert gleichzeitig die Demokratisierung von Daten.
Data Governance & Data Sharing
Mit Hilfe von Data Sharing (in Databricks: Delta Sharing) können Datenprodukte oder einzelne Datensätze durch Anwendungen und Eigentümer gemeinsam genutzt sowie über Datenkatloge (Data Catalog) hinsichtlich der Zugriffe verwaltet werden.